ML Agent - Donut Collector
SUMMARY
Using the Unity ML Agents Toolkit, a neural network was trained to control a charater who gathers donuts as quickly as possible while avoiding spikes. For details on this package see the official documentation.
https://github.com/Unity-Technologies/ml-agents
CONTROLS
Press <space> to reset the enironment.

DETAILS
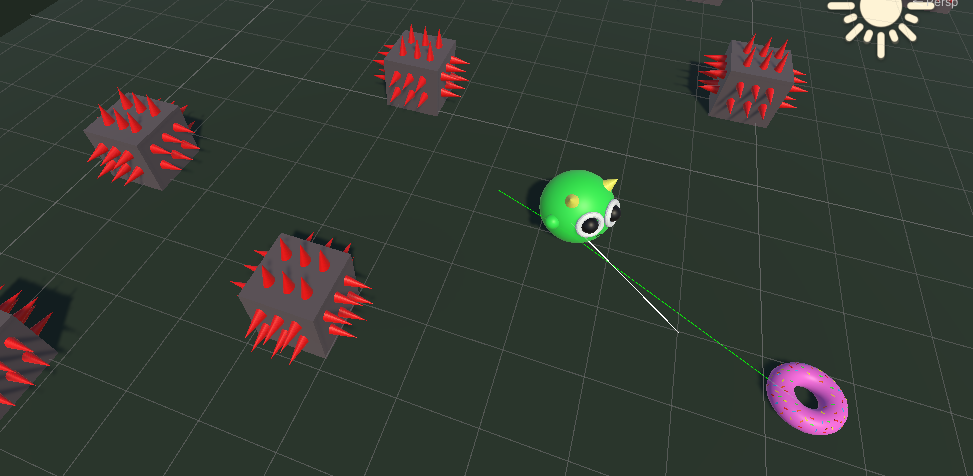
Setting: A closed environment where agent can move forwards, backwards, and turn.
Goal: Collect all the donuts while avoiding spikes.
Agent Reward Function:
- Donut collision: +10 per collision.
- Spike collision: -100 per collision. Three collisions end the session.
- Orientation: On each frame, gives (orientation factor * 0.001) , where orientation factor is +1 when facing nearest donut and -1 when facing away. Calculated with dot product between vector to donut and forwards vector. Encourages agent to face a donut.
- Nearst donut distance: On each frame, gives -1 when donut is MAX_DISTANCE away, and +0 when close. Encourages agent to move towards nearst donut.
- Hustle factor: On each frame, gives -1 for standing still and +0 when moving at max speed. Ecourages agent to move quickly.
- Hazard proximity: On each frame, gives -0.1 if a short forwards raycast collides with a hazard. Discourages getting stuck close to spikes.
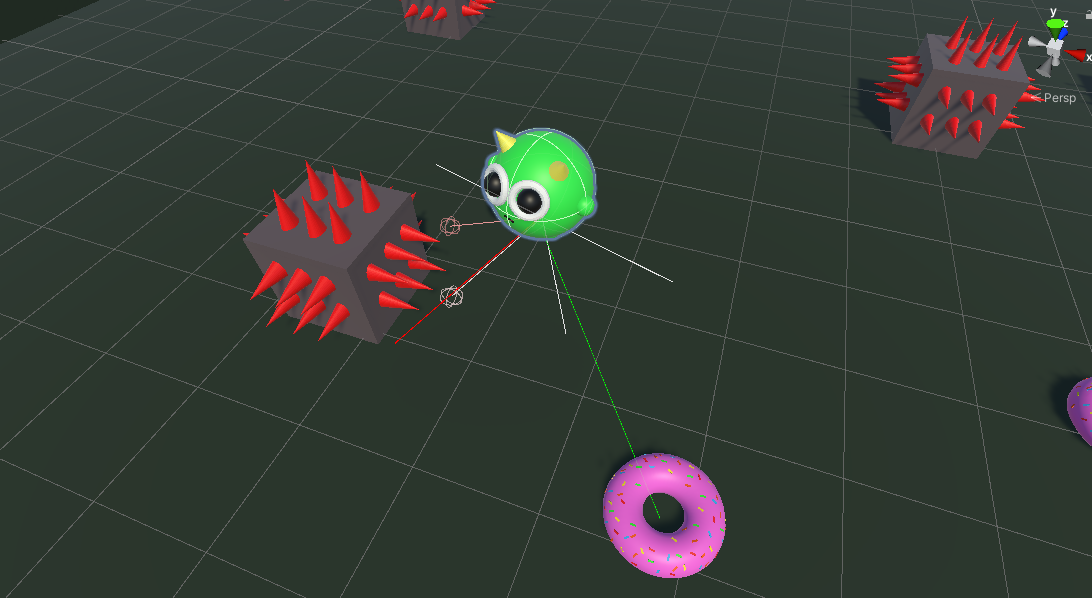
Observations (Input Values):
- Character's forwards vector (x, z components).
- Vector from character to nearest donut (x, z components).
- Distance to nearest donut.
- Five "vision" raycasts in a 180° forwards facing cone. Can detect when a donut or spike is in front or to the sides of the character.
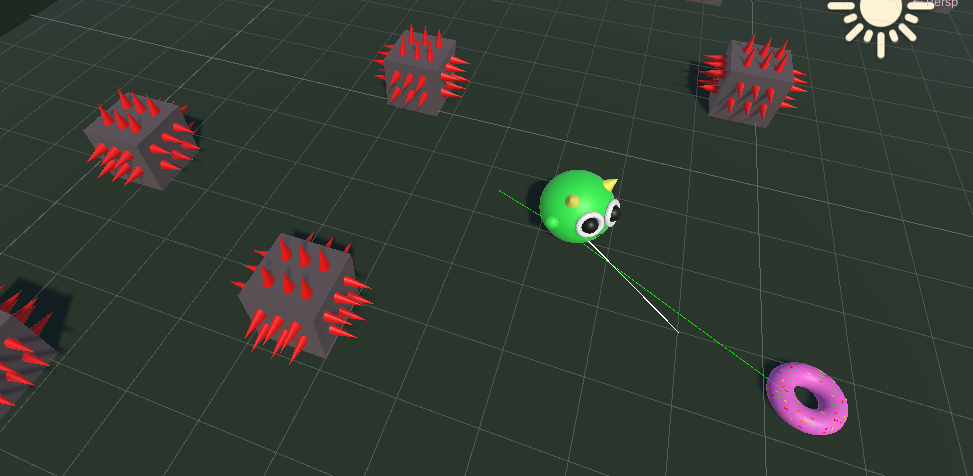
Actions (Output Values):
- Turn: -1 to turn CCW, +1 to turn CW.
- Move: -1 to move backwards, +1 to move forwards.
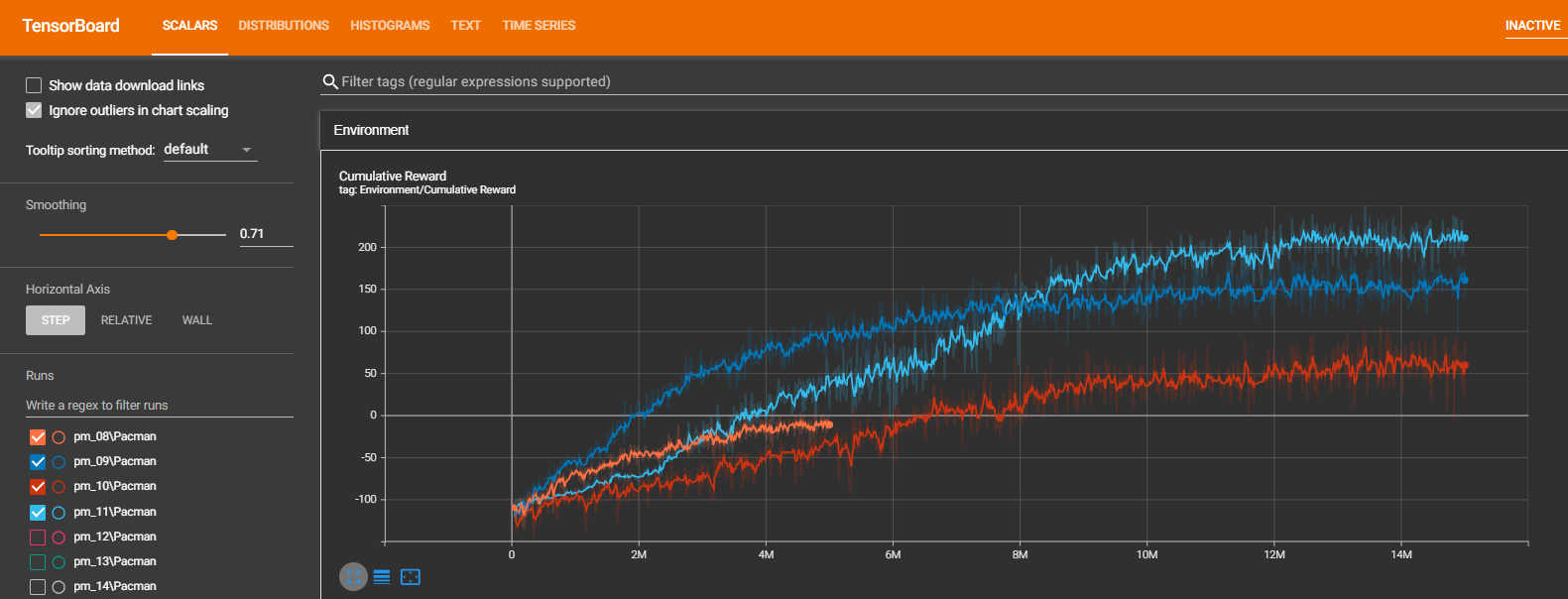
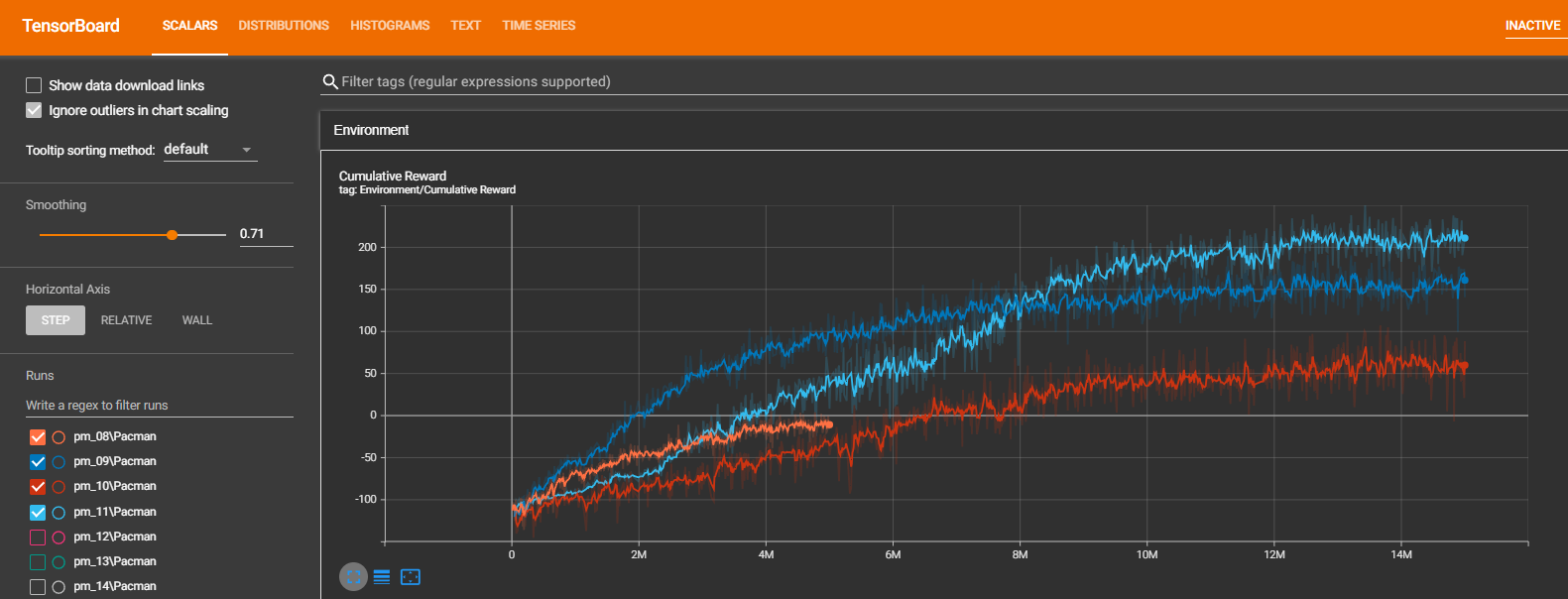
Training:
The neural network, observations vector, and reward function have undergone 15 different versions throughout this project. The most recent version, described above, is playing in the game view window. It has been trained for ~ 14M iterations, which took several days of wall time on my machine.

FUTURE DEVELOPMENT FEATURES PLANNED
* edit environment menu -- make the board more or less harsh by choosing number of donuts and spikes.
* competition mode -- test your own donut collecting skills against a trained model.

Leave a comment
Log in with itch.io to leave a comment.